다양한 OpenSource 모니터링 구성
Opensource Metrics 종류
| 툴 이름 | 수집기 | 데이터 핸들러 | 데이터 보관 | 시각화 | 비고 |
|---|---|---|---|---|---|
| NFLUXDATA | Telegraf | Telegraf | Influxdb | Grafana | 자체 UI있으나 Grafana 보다 기능이 떨어짐 |
| Elastic Stack | Metricbeat | Logstash | Elasticsearch | Kibana | |
| PROMETHUS | node_exporter | Promethus | Promethus | Grafana | 자체 UI있으나 Grafana 보다 기능이 떨어짐 |
InfluxData 테스트
- 지원 OS : Docker, Ubuntu& debian, Redhat&CentOS, Windows(64Bit)
- telegraf 설치
# wget https://dl.influxdata.com/telegraf/releases/telegraf-1.14.0_linux_amd64.tar.gz # tar xf telegraf-1.14.0_linux_amd64.tar.gz -
telegraf Metrics 설정(모니터링 을 위한 필요 Metrics 정보 취합만 설정)
- In the Telegraf environment variables file (/etc/default/telegraf) Example) USER="alice" INFLUX_URL="http://localhost:8086" INFLUX_SKIP_DATABASE_CREATION="true" INFLUX_PASSWORD="monkey123" # vi telegraf/etc/telegraf/telegraf.conf [global_tags] service = "elastic" [agent] interval = "10s" # 데이터 수집 간격 round_interval = true # 수집 간격을 반올림 여부(:00, :10, :20) metric_batch_size = 1000 # 최대 output size metric_buffer_limit = 10000 #output 에대한 최대 캐시(버퍼) 사이즈 최소 "metric_batch_size " 이상 배수 [[inputs.cpu]] #https://github.com/influxdata/telegraf/blob/release-1.14/plugins/inputs/cpu/README.md percpu = false totalcpu = true collect_cpu_time = false report_active = false [[inputs.mem]] #https://github.com/influxdata/telegraf/blob/release-1.14/plugins/inputs/mem/README.md [[inputs.swap]] [[inputs.system]] #https://github.com/influxdata/telegraf/blob/release-1.14/plugins/inputs/system/README.md fielddrop = ["n_users", "n_cpus", "uptime", "uptime_format"] [[inputs.processes]] # https://github.com/influxdata/telegraf/blob/release-1.14/plugins/inputs/processes/README.md [[inputs.diskio]] # https://github.com/influxdata/telegraf/blob/release-1.14/plugins/inputs/diskio/README.md name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"] [[inputs.netstat]] # https://github.com/influxdata/telegraf/blob/master/plugins/inputs/net/NETSTAT_README.md [[inputs.net]] [[outputs.influxdb]] urls = ["http://localhost:8086"] database = "server" - telegraf 실행
# usr/bin/telegraf --config etc/telegraf/telegraf.conf > /dev/null & - Influxdb 설치 (with docker)
# docker pull influxdb - Influxdb 실행
# docker run -p 8086:8086 \ -v $PWD:/var/lib/influxdb \ influxdb # docker exec -it influxdb influx >>show databases name: databases name ---- server _internal - Grafana 설치(with Docker)
# docker pull grafana/grafana - Grafana 실행
# docker run -d --name=grafana -p 3000:3000 grafana/grafana -
Grafana Dashboard
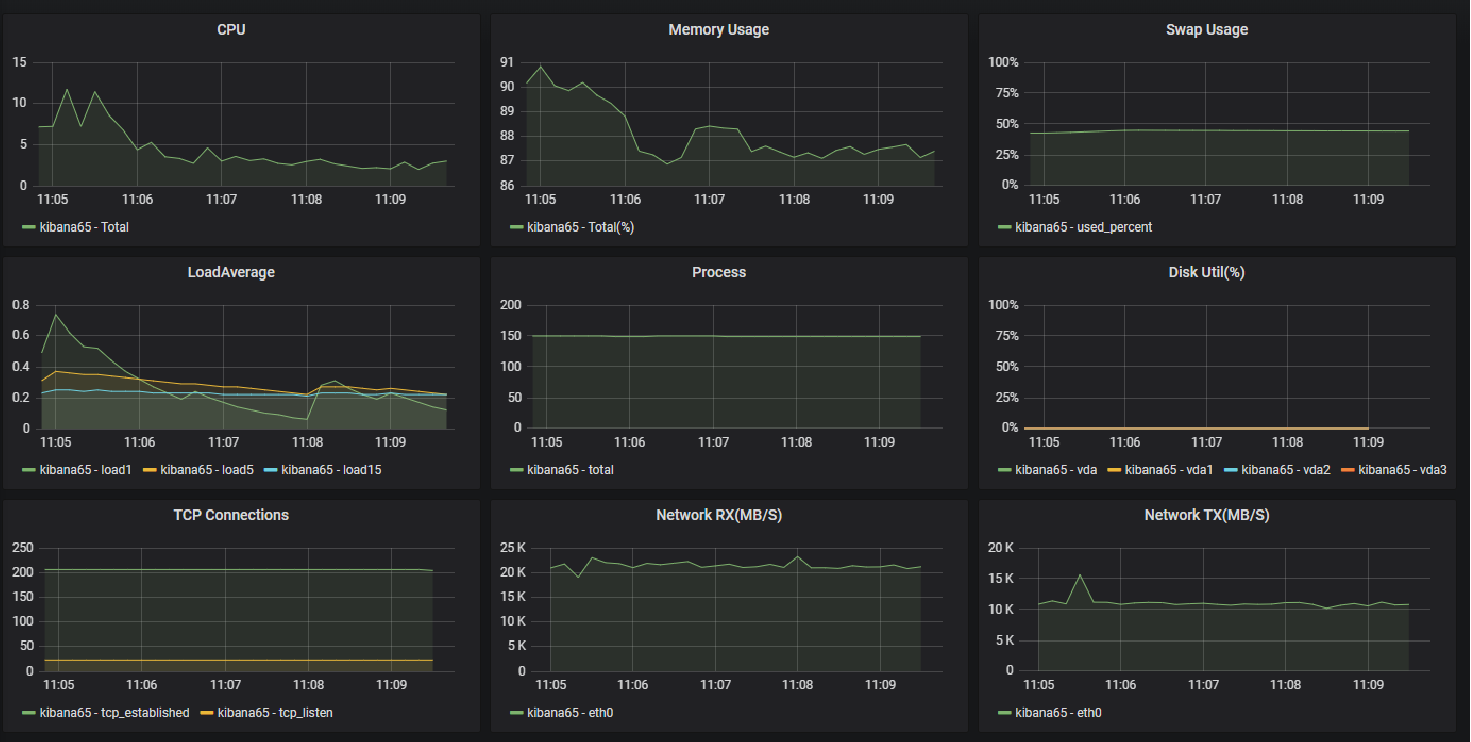
ELK (With Meticbeat) 테스트
- 지원 OS : Ubuntu& debian, Redhat&CentOS, Windows(32Bit/64Bit)
- metricbeat 설치
# wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.6.2-linux-x86_64.tar.gz # tar xvf metricbeat-7.6.2-linux-x86_64.tar.gz -
meticbeat config 설정(모니터링 을 위한 필요 Metrics 정보 취합만 설정)
# vi modules.d/system.yml # https://www.elastic.co/guide/en/beats/metricbeat/7.6/metricbeat-module-system.html - module: system period: 10s metricsets: - cpu - load - memory - network - process_summary - socket_summary - diskio # vi metricbeat.yml metricbeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false setup.template.settings: index.number_of_shards: 1 index.codec: best_compression output.logstash: hosts: ["localhost:5556"] - metricbeat 실행
# ./metricbeat & - Kibana Dashboard
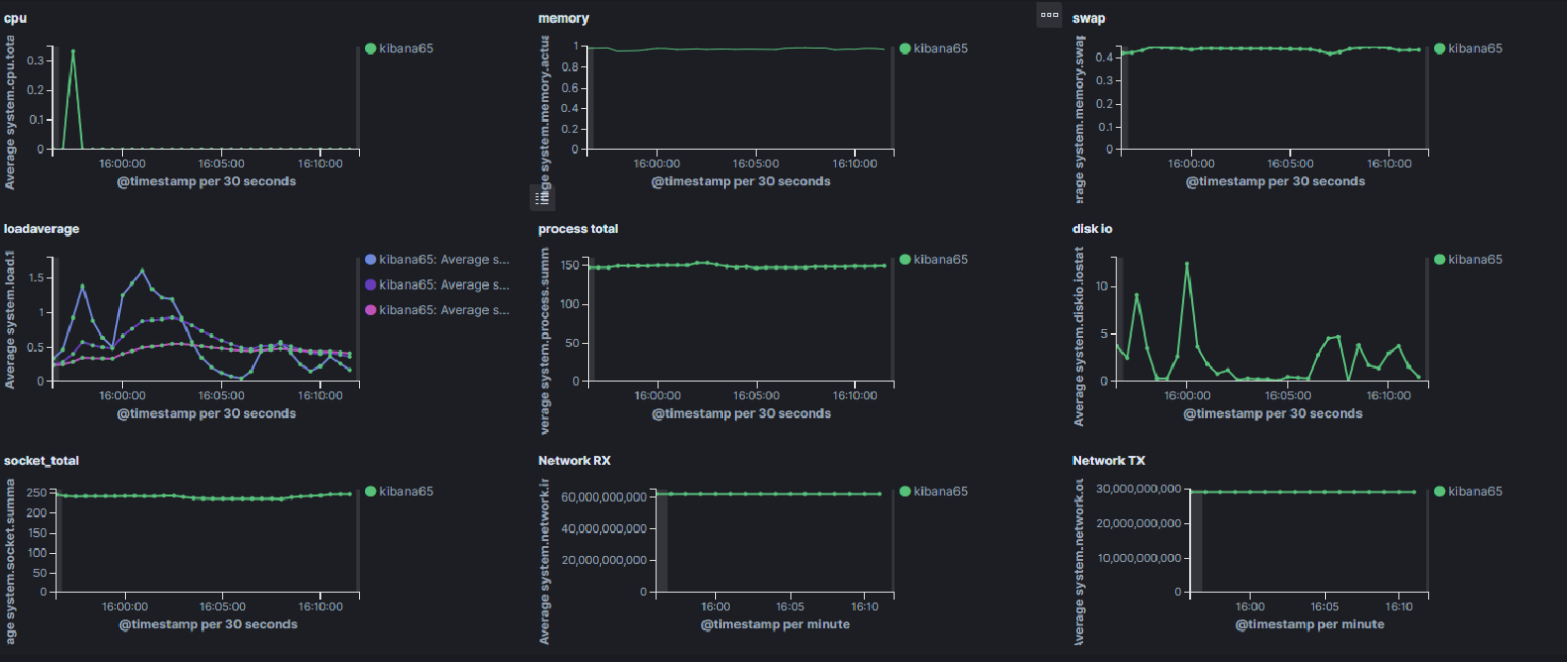
promethus 테스트
- 지원 OS : Linux(64Bit), drawin
- node_exporter 설치
# wget https://github.com/prometheus/node_exporter/releases/download/v1.0.0-rc.0/node_exporter-1.0.0-rc.0.linux-amd64.tar.gz # tar vf node_exporter-1.0.0-rc.0.linux-amd64.tar.gz - node_exporter 실행
# ./node_exporter & - node_exporter 정상 확인
> http://<server_ip>:9100/metrics - promethus 설치
# docker run \ -p 9090:9090 \ -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \ prom/prometheus - promethus config
# my global config global: scrape_interval: 10s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 10s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'metric' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['<server_ip>:9100'] - Grafana Dashboard
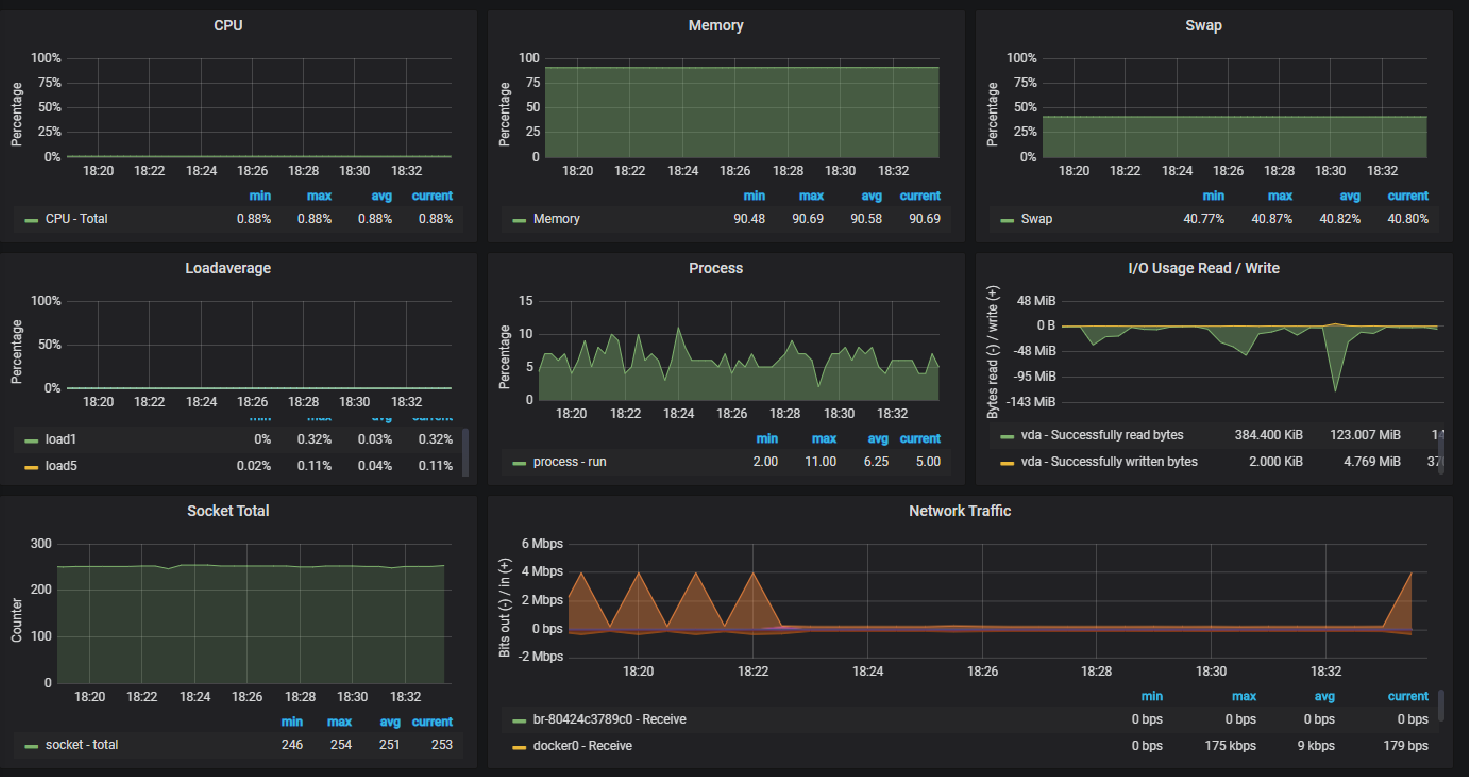
댓글남기기